create table employee(
employee_no number(3),
name varchar2(50) not null,
position varchar2(50) not null,
salary number not null,
department_no number(3) null, <-- 신입사원이라면 소속부서가 아직 결정 안되었을수 있음으로!
constraint employee_pk primary key (employee_no),
constraint department_fk foreign key (department_no)
references department (department_no) on delete cascade <--요 정의는 자식 테이블이 참조하고 있기 때문에 부모테이
블을 삭제(drop)할수 없다는 정의! data define language + 구분할 개념.. 부모테이블 전체가 아닌, 테이블의 행(레코드)를
삭제할 경우 자식테이블의 참조 값도 없어짐.
내 예측엔 on delete cascade로 ddl 했을때 참조되는 부모 테이블을 변경시 , 자식테이블의 컬럼(fk)만 비워질 것이라
생각했는데.. 결과는 삭제한 fk를 갖고 있던 자식 테이블의 모든 레코드가 삭제 되었다! 아래는 테스트 코드
CREATE TABLE DEPARTMENT(
DEPARTMENT_NO NUMBER(3,0),
DEPARTMENT_NAME VARCHAR2(50) NOT NULL,
LOCATION VARCHAR2(50),
CONSTRAINT DEPARTMENT_PK PRIMARY KEY (DEPARTMENT_NO)
);
INSERT INTO department VALUES(1,'영업부','강남구 논현동')
INSERT INTO department VALUES(2,'인사부','강남구 역삼동')
INSERT INTO department VALUES(3,'법무부','강남구 삼성동')
INSERT INTO department VALUES(4,'전략기획및 개발','강남구 삼성동')
create table employee(
employee_no number(3),
name varchar2(50) not null,
position varchar2(50) not null,
salary number not null,
department_no number(3) null,
constraint employee_pk primary key (employee_no),
constraint department_fk foreign key (department_no)
references department (department_no) on delete cascade
)
INSERT INTO employee
VALUES(1,'장호','부장','5000000000',4)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(2,'홍길동','사원','500',4)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(3,'강길동','사원','500',4)
DELETE FROM department WHERE department_no = 4
SELECT * FROM employee
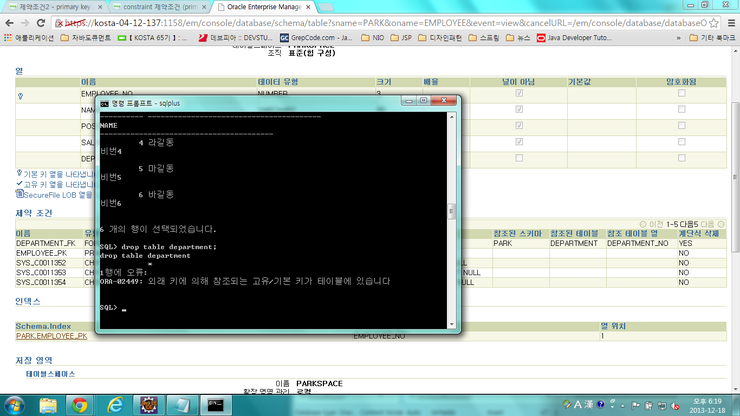
아래의 경우 drop table department; 했을 경우 실패했으나 ,, drop table department cascade constraint; 로 지워줄수있음.
물론 테이블의 삭제가 일반적인 일은 아님.(데이터가 다 날아감으로)
흠.. 직원 a씨는 인사부서 였는데.. 인사부(human resource)가 사라졌다면.. 직원 a씨의 전체 정보를 삭제할까?
아니면 컬럼만 삭제할까?
구분할 개념
테이블 생성시.. 제한 조건(constraint)로 foregn key references 부모 테이블 (칼럼이름) on delete cascade 의 경우
참조 무결성을 위해 부모 테이블의 드랍에 제한을 거는 것이고..
drop table 부모테이블 cascade constraint 의 경우는.. 자식 객체의 fk 칼럼의 레퍼런스(참조)속성을 날려버린다는
의미 같음. (해당 칼럼을 삭제하진 않을듯함?)
)
SELECT * FROM MEMBERINFO;
SELECT NAME PW FROM MEMBERINFO;
SELECT NAME FROM MEMBERINFO WHERE ID = 'id3';
UPDATE MEMBERINFO SET NAME ='나길동' WHERE ID = 'id2';
UPDATE MEMBERINFO SET ID =5 WHERE NAME = '마길동';
INSERT INTO memberinfo VALUES(4,'하길동','비번66')
INSERT INTO MEMBERINFO(ID,NAME) VALUES('id5','5');
INSERT INTO MEMBERINFO values('id4','라길동','4');
DELETE FROM MEMBERINFO WHERE ID = 'id4';
ALTER TABLE MEMBERINFO DROP COLUMN ID;
ALTER TABLE MEMBERINFO DROP CONSTRAINT ID_PK;
ALTER TABLE MEMBERINFO ADD(ADDRESS VARCHAR2(50));
ALTER TABLE MEMBERINFO MODIFY (ADDRESS VARCHAR2(100));
ALTER TABLE MEMBERINFO ADD CONSTRAINT ID NUMBER PRIMARYKEY;
ALTER TABLE MEMBERINFO ADD PRIMARY KEY(ID NUMBER(6,2));
ALTER TABLE MEMBERINFO MODIFY (ID NUMBER(6,0)[PRIMARY KEY]);
ALTER TABLE MEMBERINFO ADD(ID2 NUMBER CONSTRAINT PRIMARY KEY);
ALTER TABLE MEMBERINFO MODIFY (ID NUMBER);
DROP TABLE MEMBERINFO2;
CREATE TABLE MEMBERINFO2(ID NUMBER(6,0) PRIMARY KEY, PW VARCHAR2(20), NAME VARCHAR2(20));
ALTER TABLE MEMBERINFO2 MODIFY(ID NUMBER(6,0) NOT NULL);
DROP TABLE DEPARTMENT;
CREATE TABLE DEPARTMENT(DEPARTMENT_NO NUMBER(3,0) PRIMARY KEY, DEPERTMENT_NAME VARCHAR2(50) NOT NULL,
LOCATION VARCHAR2(50));
DELETE FROM department WHERE department_no = 4
drop table employee
CREATE TABLE DEPARTMENT(
DEPARTMENT_NO NUMBER(3,0),
DEPARTMENT_NAME VARCHAR2(50) NOT NULL,
LOCATION VARCHAR2(50),
CONSTRAINT DEPARTMENT_PK PRIMARY KEY (DEPARTMENT_NO)
);
INSERT INTO department VALUES(1,'영업부','강남구 논현동')
INSERT INTO department VALUES(2,'인사부','강남구 역삼동')
INSERT INTO department VALUES(3,'법무부','강남구 삼성동')
INSERT INTO department VALUES(4,'전략기획및 개발','강남구 삼성동')
UPDATE department SET location = '제주도 성남시'
UPDATE department SET department_name = '전략기획' WHERE department_no = 4
UPDATE department SET location = '논현동' WHERE department_no = 1;
UPDATE department SET location = '역삼동' WHERE department_no = 2;
UPDATE department SET location = '삼성동' WHERE department_no = 3;
UPDATE department SET location = '동동' WHERE department_no = 4;
INSERT INTO department(department_no,department_name,location) VALUES(5,'')
SELECT * FROM department
SELECT * FROM department ORDER BY department_no ASC
create table employee(
employee_no number(3),
name varchar2(50) not null,
position varchar2(50) not null,
salary number not null,
department_no number(3) null,
constraint employee_pk primary key (employee_no),
constraint department_fk foreign key (department_no)
references department (department_no) on delete cascade
)
INSERT INTO employee
VALUES(1,'장호','부장','5000000000',4)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(2,'홍길동','사원','500',4)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(3,'강길동','사원','30000',4)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(4,'나길동','ㄹㅇㄹㅇ','3004400',3)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(5,'다길동','ㄷㄷ','3003300',2)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(6,'라길동','ㅂㅂ','6630000',1)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(7,'길동','ㅂㅂ','66320000',3)
INSERT INTO employee(employee_no,name,position,salary,department_no)
VALUES(8,'길동이','ㅂㅂ','66000',3)
DELETE FROM department WHERE department_no = 4
SELECT * FROM employee WHERE department_no IN(1,3) ORDER BY name ASC
SELECT * FROM employee WHERE department_no NOT IN(1,3) ORDER BY name ASC
SELECT * FROM employee WHERE department_no IN(1,3) ORDER BY department_no ASC
SELECT * FROM employee WHERE name LIKE('%동')
SELECT * FROM employee WHERE name LIKE('%동%')
SELECT * FROM employee WHERE name LIKE('길%')
SELECT * FROM employee WHERE name LIKE('__동')
SELECT * FROM employee WHERE name LIKE('__') ORDER BY salary DESC
SELECT * FROM employee WHERE name LIKE('%') ORDER BY salary DESC
SELECT * FROM employee WHERE name LIKE('_동')
SELECT * FROM employee WHERE name NOT LIKE('_동')
글고 조인 연산시.. 테이블의 별칭을 줄수 있다. 왜냐면 네임스페이스 처럼
이름 식별을 위해서~ 글고 뒤에 오더정렬을 안해주면 입력 순서가 유지가 안된다.
그럼으로 이를 통해 dbms가 데이터를 저장하는 방식이 map<pk,Object data~~> 임을
유추할수 있다. 검색 속도 증가를 위한 인덱싱이란 무얼까?
SELECT * FROM employee e, department d <--불필요한 정보까지 싸그리 가져온 경우
WHERE e.salary > '300600' AND d.department_name = '법무부' AND e.name LIKE('_길_')
ORDER BY e.name ASC
아참.. where 조건절을 ()로 묶어줄 수 있다.
SELECT e.name FROM employee e, department d
WHERE e.salary > '30000' AND d.department_name = '법무부' AND e.name LIKE('_길_')
ORDER BY e.name ASC
SELECT * FROM employee
alter table employee modify(department_no number(3) foreign key);
(추가)난 여전히 학원 과정(아주 얕게 RDB 수업 & JDBC를 활용한 CRUD 테스트 실습)과는 별개로
공부및 추가 학습을 하고 있다. (오라클 DBMS 아키텍처및 각종 쿼리와 최적화, 테이블 설계, 정규화
비정규화등..) RDB도 제대로 이해를 못하고.. 빅데이터를 알게 되었다.(대용량 DB 아니다)

RECENT COMMENT